RSS
RSS
 13 ноября 2020
13 ноября 2020  gromych
gromych ЗАЧЕМ ИСПОЛЬЗОВАТЬ SETANALYSIS
Анализ множеств (Set Analysis) позволяет создать выбор, отличный от активного, в используемой в таблице или графике. Созданная группа позволяют сравнить агрегирование этой группы и группы из текущего выбора.
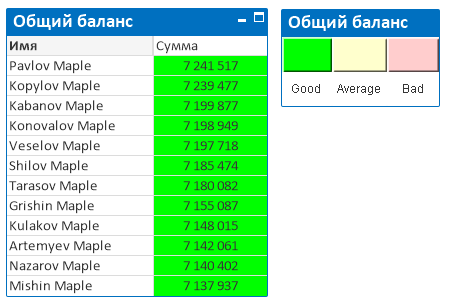
Эти агрегаты позволяют сравнить, например, продажи текущего месяца и месяца в предыдущем году.
Анализ множеств (Set Analysis) изменяет контекст только для выражения, которое использует его. Другое выражение без какого-либо выбора получит контекст по умолчанию, стандартный выбор или группу альтернативного состояния.
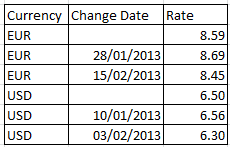
Множества могут использоваться в функциях агрегирования.Функции агрегирования как правило агрегируют множества возможных записей, определенных текущей выборкой. Однако выражением множества может быть определено альтернативное множество записей. Поэтому множество имеет принципиальное сходство с выборкой. В случае использования выражение множества всегда начинается и заканчивается фигурными скобками, например {BM01}.
Анализ множеств применим, как в QlikView, так и в Qlik Sense.