 RSS
RSS
 13 ноября 2020
13 ноября 2020  gromych
gromych 
Слияние таблиц для новичка: JOIN
Продолжаю серию статей по работе с таблицами. На прошлой неделе уже писал о том, как работать с CONCATENATE для объединения таблиц по строкам, а в этой статье расскажу, как добавлять столбцы к уже загруженным таблицам данных с помощью JOIN.
Предыстория
В прошлой статье мы рассматривали пример, в котором компания X объединяла данные по сотрудникам отдела продаж с другим офисом компании в другом регионе. Мы объединяли данные таблицы, используя CONCATENATE, рассмотрев разницу между скрытым и открытым объединением строк.
Новые требования
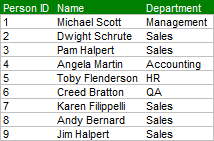
Теперь после получения единой таблицы появляются новые требования, а именно объединить данные по управлению персоналом с новой таблицей по сотрудникам так, чтобы были доступны описания функционала работы. Итак, как же это сделать?
Простая загрузка таблиц
Первый способ решения этой задачи – загрузить таблицу как есть. Получится вот такая модель данных.
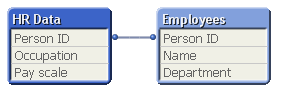
Технически такой способ решения не является ошибкой, ну лучше объединить представленные данные в единую таблицу, что позволит нам:
- Упростить модель данных.
- Опять же проще поддерживать модель данных.
JOIN
Когда добавляем JOIN до скрипта загрузки LOAD, QlikView не загружает данные в единую таблицу, а объединяет данные с предыдущей таблицей.

В этом случае QlikView сравнивает все общие поля в двух таблицах и объединяет строки из двух таблиц по совпадающим полям.
Дополнительно можно определить таблицы, с которыми будет идти работа по объединению данных. Если имя таблицы не определено, по умолчанию QlikView считает, что данные должны быть объединены с последней загруженной таблицей.
НА ЗАМЕТКУ! Рекомендую всегда определять имя таблицы, с которой будет вестись работа.

Типы объединений Join
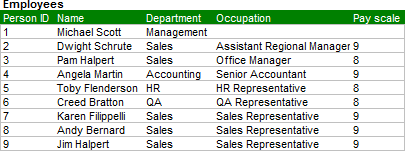
Когда вы посмотрите на наши таблицы, то увидите, что не все ID сотрудников имеют совпадения в таблицах. Таблицы Employees содержат поля сотрудник, Michael Scott, которого нет в таблице данных по управлению персоналом. А данные по управлению персоналом содержат также данные по секретарю, которого нет в другой таблице.
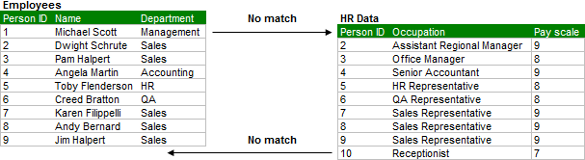
Когда мы выполняем функцию стандартного объединения, таблицы объединяются так, что связанные записи из двух таблиц отображаются в одной и той же строке. Записи без связи получаются пустыми для остальных столбцов (см. рисунок ниже):

Это практически та таблица, которую мы хотели получить в итоге, но здесь, по-прежнему, есть данные по секретарю, которые мы должны исключить. Эту задачу легко решить, определив тип объединения данных.
У нас есть следующие варианты объединения данных, или JOIN:
- INNER: Только записи, которые представлены в двух таблицах входят в объединённую таблицу. В нашем случае это означает, что и первый сотрудник из таблицы 1 с ID 1 (Michael Scott) и ID 10 (секретарь) были бы исключены из итоговой таблицы.
- OUTER: Все записи из двух таблиц будут включены в итоговую таблицу, не важно имеют они общие данные по строкам или нет. Получается такой же итог как использование обычного объединения.
- LEFT: Все записи из первой таблицы будут включены в итоговую таблицу и только те записи из второй таблицы, которые имеют одинаковое значение с первой таблицей. В нашем примере это означает, что сотрудник ID 1 (Michael Scott) будет включен в итоговую таблицу иID 10 (секретарь) исключен, поскольку у этой строки нет связанных данных с первой таблицей.
- RIGHT: Все записи из второй таблицы будут включены в объединенную таблицу, а также только те строки из первой таблицы, у которых есть одинаковые записи со второй таблицей. В нашем примере это означает, что ID 10 (секретарь) будет включен в итоговую таблицу и ID 1 (Michael Scott) будет исключен.
Поскольку мы хотим иметь полную таблицу сотрудников и добавить связанные значения из данных по УП, используем LEFT JOIN.
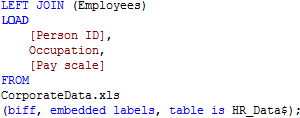
Получим такую таблицу:

- Учебный центр по технологиям анализа данных и BI: расписание/запись на учебные курсы, тестирование разработчиков — https://education.biconsult.ru/
- Присоединяйтесь к QUBIC – сообщество профессионалов в области BI! Наши страницы в соц.сетях – расписание учебных курсов, бесплатные учебные материалы, анонсы мероприятий: https://vk.com/club165575964 и https://www.facebook.com/qubicspb
- Неофициальный форум разработчиков QlikView & Qlik Sense Russian forum
- Канал на Youtube – много обучающих видео и записи вебинаров
- Готовые решения “Конструктор финансовой отчетности” и “Анализ продаж”
 Опубликовано в рубрике
Опубликовано в рубрике  Метки:
Метки: